Nyyon · Blog
The Startup Data Stack That Actually Drives Growth
A practical guide to startup data tools by stage, from product analytics to warehouses and activation, so founders build systems that drive decisions.
The best startup data stack is the one that reduces uncertainty before it increases infrastructure.
Most data conversations in startups begin in the wrong place. Someone asks whether the company should use Snowflake or BigQuery, Fivetran or Airbyte, Tableau or Looker. That is already a late-stage question disguised as strategy. The earlier question is simpler and more dangerous: what decision is currently being made with weak evidence?
If the answer is unclear, the company does not have a data problem. It has a management problem with software attached.
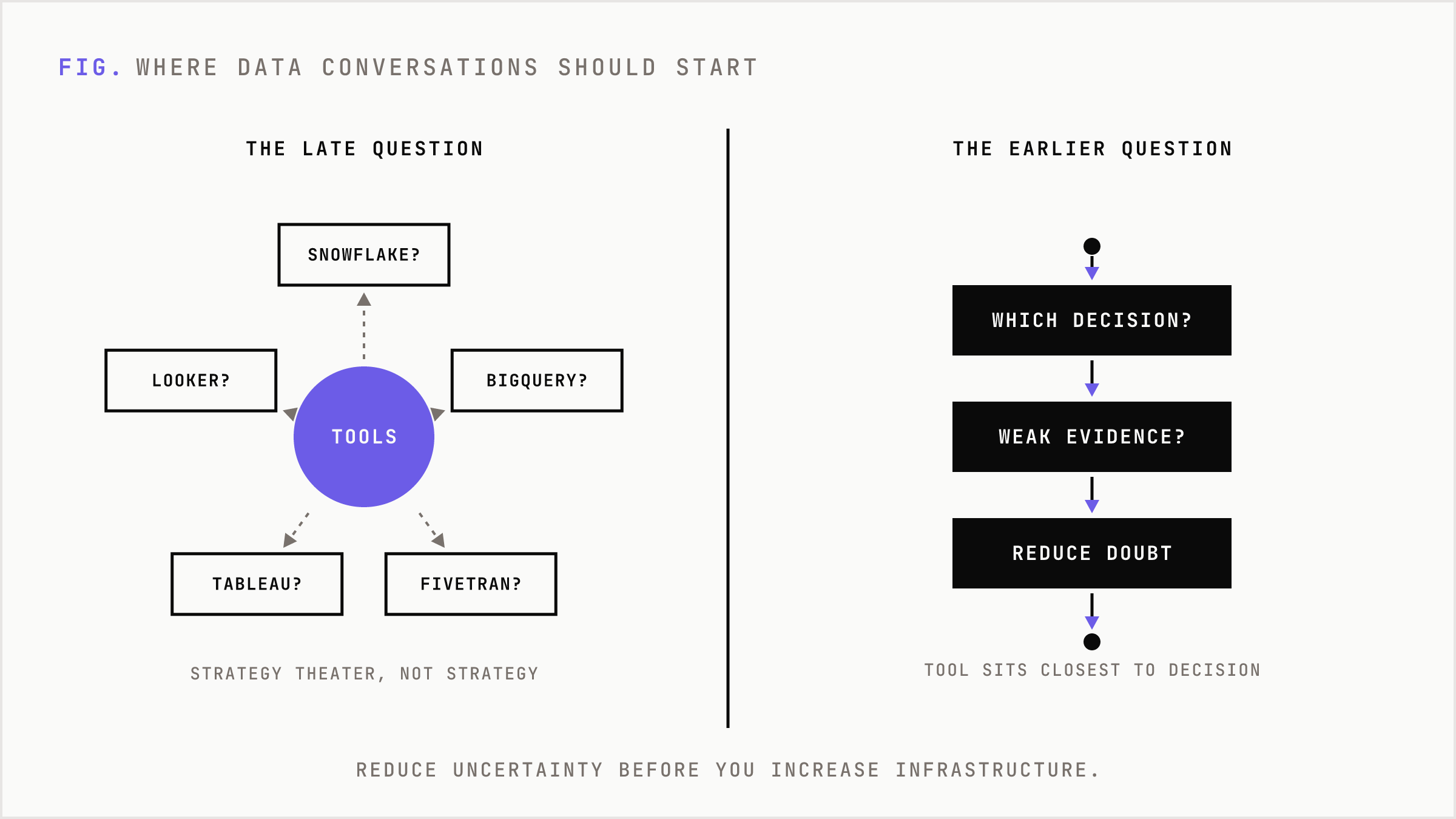
The stack is not the strategy
A modern data stack can be useful. It can also become a theater set. Warehouses, pipelines, transformation layers, dashboards, reverse ETL, observability, semantic layers, and AI query assistants look like maturity from a distance. Up close, many are just cost centers waiting for a real operating cadence.
Startups do not need more data first. They need faster uncertainty reduction. That means the first tool should sit closest to the decision. Product decisions belong near product behavior. Marketing decisions belong near acquisition channels. Sales decisions belong near CRM activity. Finance decisions belong near billing and cash.
The warehouse becomes important when these domains collide. Until then, centralization is often a tax on speed.
Pre-PMF data is not business intelligence
Before product market fit, the job is not reporting. The job is learning. You are trying to find the repeated behavior that predicts a real customer, not produce polished charts for a board deck.
At the idea or MVP stage, the stack can be brutally small: GA4, Search Console, Stripe or CRM native reports, and Sheets. That is not primitive. It is appropriate. You need to know where users came from, whether they signed up, whether they paid, and what they did before they disappeared.
For a pre-seed or seed SaaS company, PostHog is often the cleanest default because it compresses several early jobs into one surface: product analytics, session replay, feature flags, experiments, surveys, and basic behavioral analysis. Amplitude and Mixpanel are strong alternatives when the product and growth teams need fast funnel and cohort analysis without writing SQL.
The commercial logic is simple. Early teams have scarce attention, not just scarce budget. A bundled product analytics tool substitutes for four separate buying decisions. It also puts the founder, PM, designer, and engineer in the same evidence base. That matters more than architectural elegance.
Track the events that change behavior
The most valuable early data work is not choosing a vendor. It is naming the product.
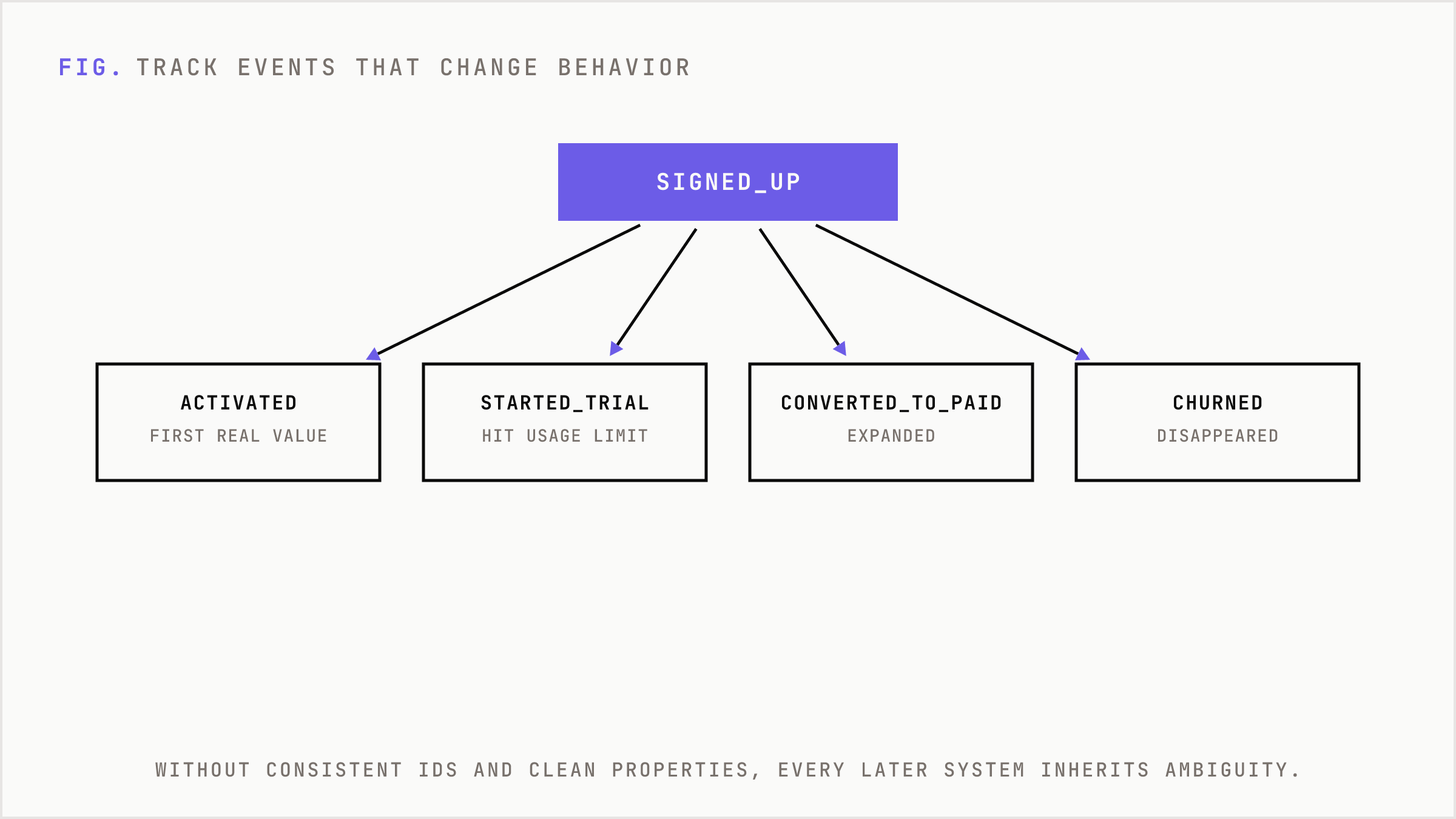
A startup should know the difference between a user who signed up and a user who activated. It should know which action marks first value. It should know which accounts invited teammates, hit a usage limit, started a trial, converted to paid, expanded, or churned.
A useful early event taxonomy might include signed_up, activated, created_project, completed_core_action, invited_user, hit_usage_limit, started_trial, converted_to_paid, expanded, and churned. Each event should carry properties like user_id, account_id, plan, source, medium, campaign, role, signup date, activation date, company size, industry, and lifecycle stage.
This sounds basic because it is. It is also where most companies fail. Without consistent IDs and clean properties, every later system inherits ambiguity. The warehouse does not fix it. AI does not fix it. A more expensive dashboard does not fix it.
The warehouse arrives when questions cross systems
Product analytics should usually come before the warehouse. The warehouse becomes necessary when the company starts asking questions that no single operational tool can answer.
Which acquisition channels create retained users, not just signups? Which accounts saw three demos, activated two users, and then failed to convert? Which usage patterns predict expansion? Which ad campaigns produce high-LTV customers after support costs and refunds? Which onboarding step is the choke point for the segment sales cares about?
These are cross-system questions. They require product events, website analytics, CRM data, billing data, ad platform data, lifecycle email data, and sometimes support data. That is when BigQuery, Snowflake, or another warehouse starts to earn its keep.
For many startups, BigQuery is attractive because it is easy to start small and fits naturally with GA4 export and Google Cloud workflows. Snowflake is a common enterprise-grade choice when governance, performance isolation, and larger data teams matter. DuckDB has become useful for tiny, local, or engineering-led analysis where a full warehouse would be absurd.
The point is not that one warehouse wins. The point is that the warehouse should appear after the business has cross-functional questions worth centralizing.
Ingestion is a buy versus build decision

Once the warehouse exists, the next bottleneck is getting data into it without turning engineers into connector janitors.
Fivetran is strong when engineering time is more expensive than connector cost. It is a classic executive purchase: pay money to remove maintenance risk. Airbyte and dlt make more sense when sources are strange, budgets are tight, or the team wants control. dlt is especially natural for Python-heavy teams moving messy operational data into structured datasets.
This is a substitution dynamic. The buyer is not choosing between tools in a vacuum. They are choosing between vendor spend, engineering cycles, pipeline reliability, and opportunity cost. At seed, custom scripts may be fine. At Series A, broken CRM syncs before a board meeting are no longer charming.
Transformation is where trust is manufactured
A warehouse full of raw tables is not a truth layer. It is storage.
dbt became the default transformation layer because it gives analytics teams a disciplined way to turn raw data into modeled data using SQL, tests, documentation, and version control. The business value is not the tool itself. The value is that active_account, net_revenue_retention, activated_user, and marketing_qualified_lead stop being private definitions trapped inside different dashboards.
This is the point where startups begin to understand that metrics are products. They have owners. They have definitions. They have dependencies. They can break. They require maintenance.
Dashboards then become outputs of a model, not arguments about reality.
Dashboards are usually overbuilt
Early dashboards should be few and sharp. A founder needs to see whether users reach activation, whether activated users retain, which acquisition channels produce retained customers, which accounts are likely to convert or churn, and what the team should do this week.
Metabase is a strong default for startups because it is accessible, flexible, and does not require the cultural overhead of enterprise BI. Looker Studio is fine for lightweight marketing views and client-facing reports. Tableau, Power BI, Sigma, Looker, and Lightdash can all make sense later depending on the team, governance needs, and existing ecosystem.
The mistake is treating dashboards as an end state. A dashboard that does not change a workflow is just a prettier archive. If no one owns the metric, reviews it on a cadence, and takes action from it, the company has purchased visibility without control.
Reverse ETL is not a default
Reverse ETL tools like Hightouch and Census are valuable when trusted warehouse data needs to trigger action in sales, marketing, lifecycle, support, or ads. They are not valuable because activation sounds strategic.
Buy reverse ETL when there is a repeatable workflow: sync product qualified leads to Salesforce, push churn-risk accounts into HubSpot, send high-LTV cohorts to ad platforms, update lifecycle email journeys based on onboarding stage, or route expansion opportunities to customer success.
The prerequisite is trust. If the warehouse contains shaky identity resolution and contested definitions, reverse ETL turns bad data into automated damage. It does not just show the wrong number. It moves the wrong account into the wrong workflow.
AI makes bad data louder
The AI-native angle is misunderstood. LLMs make analytics easier to access, but they do not solve identity resolution, missing events, broken schemas, duplicate accounts, or untrusted metrics. They often amplify those problems because the interface feels confident even when the substrate is weak.
Natural-language querying is useful when the underlying data model is clean. Without a semantic layer or disciplined metric definitions, it becomes a faster way to generate plausible nonsense. A founder asking an AI analyst for CAC by channel is still dependent on whether UTMs, ad click IDs, CRM contacts, opportunities, subscriptions, refunds, and account IDs were stitched correctly.
This is why data quality has moved from back-office hygiene to a visible budget line. AI increases the value of clean data because it expands the number of people who can consume it. It also increases the cost of bad data because more decisions can be made from a flawed answer.
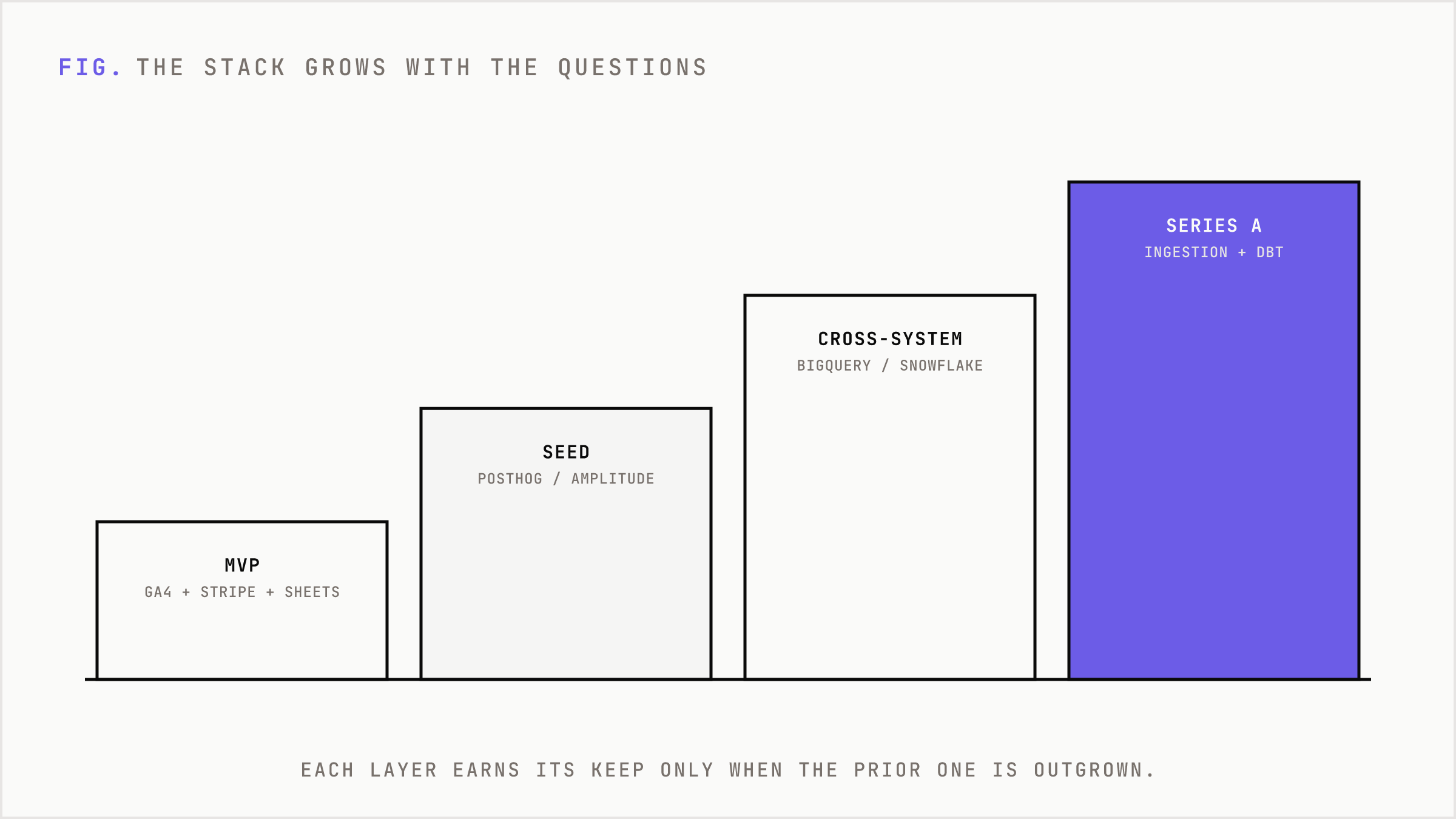
The stage map is the buying map
At MVP, use native reports and spreadsheets. At seed, add product analytics and lightweight dashboards. If the company has a go-to-market motion, connect product behavior to CRM, website, ads, and revenue. At Series A, centralize data in a warehouse, add ingestion, model it with dbt, and expose governed dashboards. At Series B and beyond, invest in activation, observability, governance, and workflow automation.
This sequence is not conservative. It is aggressive in the right direction. It spends money when the next layer unlocks decisions that the previous layer could not support.
A PLG company should obsess over event volume and pricing before logging every hover, scroll, heartbeat, and background poll into a paid analytics product. A B2B SaaS company should prioritize account-level identity across product, CRM, and billing. An AI SaaS company should segment retention and cost by model, feature, use case, and customer cohort. A marketplace or ecommerce company should connect acquisition, product behavior, order data, margin, refunds, and repeat purchase behavior before claiming it understands growth.
Different businesses need different stacks because they have different economic engines.
The real market expansion
The long-term market is not just bigger warehouses or better dashboards. It is the movement of data from reporting into operations.
First, companies collected data. Then they visualized it. Then they modeled it. Now they are using it to trigger work: sales outreach, onboarding nudges, renewal plays, support prioritization, pricing tests, fraud review, ad suppression, and expansion campaigns.
That shift changes the buyer. Data tooling no longer sells only to analytics leaders. It sells to growth, RevOps, product, finance, customer success, and founders who want tighter feedback loops between customer behavior and company action.
The winning tools will not be the ones with the longest feature list. They will be the ones that sit inside real workflows, preserve trust, and reduce the number of human handoffs between signal and action.
The rule
Do not buy a data tool because it completes a stack diagram. Buy it because a decision is blocked.
If users are leaking from onboarding, install product analytics and replay. If paid acquisition looks efficient but retention is unknown, connect channel data to activation and revenue. If sales and product disagree on account health, centralize product, CRM, and billing data. If modeled data is trusted and teams need to act on it, add reverse ETL. If AI is going to answer business questions, invest in schemas, IDs, definitions, and quality first.
The best startup data stack is not the most modern. It is the one that tells the company what to do next, soon enough to matter.
FAQ
What is the best data stack for an early-stage startup?
For most early startups, use PostHog for product behavior, GA4 and Search Console for acquisition, Stripe or CRM reports for revenue, and Metabase or Looker Studio for simple dashboards. Add a warehouse only when cross-system questions become painful.
When should a startup add a data warehouse?
Add a warehouse when important questions require data from multiple systems, such as product usage, CRM activity, billing, ads, lifecycle email, and support. If one tool can answer the question, a warehouse may be premature.
Should product analytics come before business intelligence?
Usually yes. Before product market fit, the key questions are behavioral: who activates, who retains, where users get stuck, and which features correlate with conversion. Product analytics answers these faster than a warehouse-first BI setup.
Do startups need reverse ETL?
Not by default. Reverse ETL becomes useful when trusted warehouse data needs to trigger repeatable workflows, such as sending product qualified leads to sales, churn-risk accounts to customer success, or high-value cohorts to ad platforms.
Can AI replace a clean data model?
No. AI can make data easier to query, but it does not fix missing events, inconsistent IDs, duplicate accounts, broken schemas, or unclear metric definitions. It makes clean data more valuable and bad data more dangerous.