Nyyon · Blog
Local AI Inference: Split Building From Operating
Local AI inference wins when teams build models centrally but operate them near the data, workflow, and customer decision.
The next hardware race is local AI inference, not bigger dashboards around rented intelligence. The question is whether teams should keep building models in the cloud or split building from operating. The answer: train, tune, and evaluate where the best shared infrastructure lives, but operate inference close to the customer, the data, and the workflow when privacy, latency, or unit economics matter.
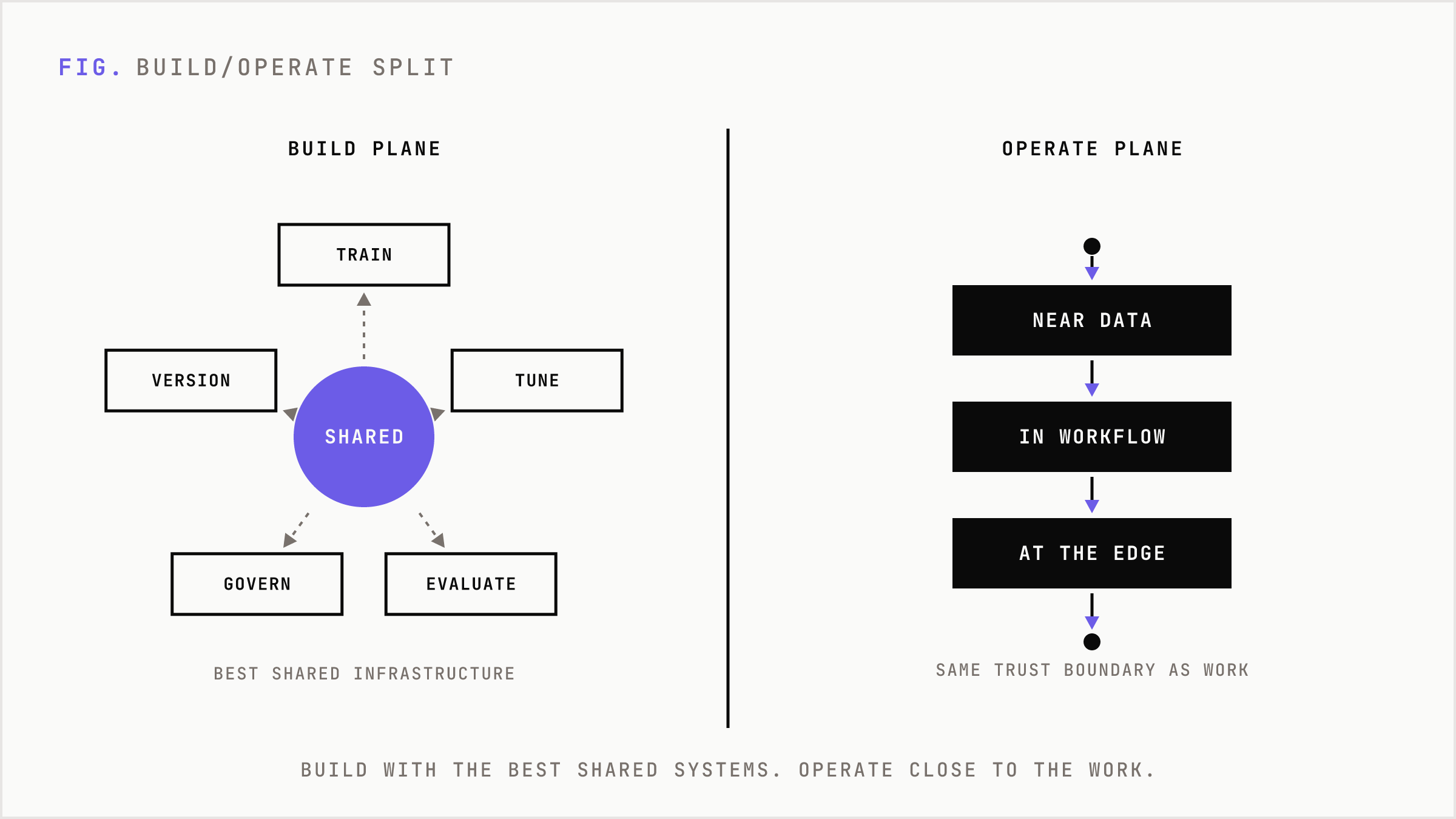
That split matters because the AI market keeps confusing two very different jobs. Building is the work of creating, evaluating, tuning, governing, and versioning models. Operating is the work of running those models inside business workflows where speed, permissions, cost, and context decide whether the system is useful.
Local AI inference is the execution of an AI model near the data or user instead of sending every request to a remote shared model API.
The dominant pattern is renting every decision from the cloud
The default pattern is simple. A product, marketing system, support queue, or sales workflow sends text, metadata, files, and instructions to a remote model API. The API returns a prediction, summary, answer, label, or draft. The team pays per token, per request, or per seat.
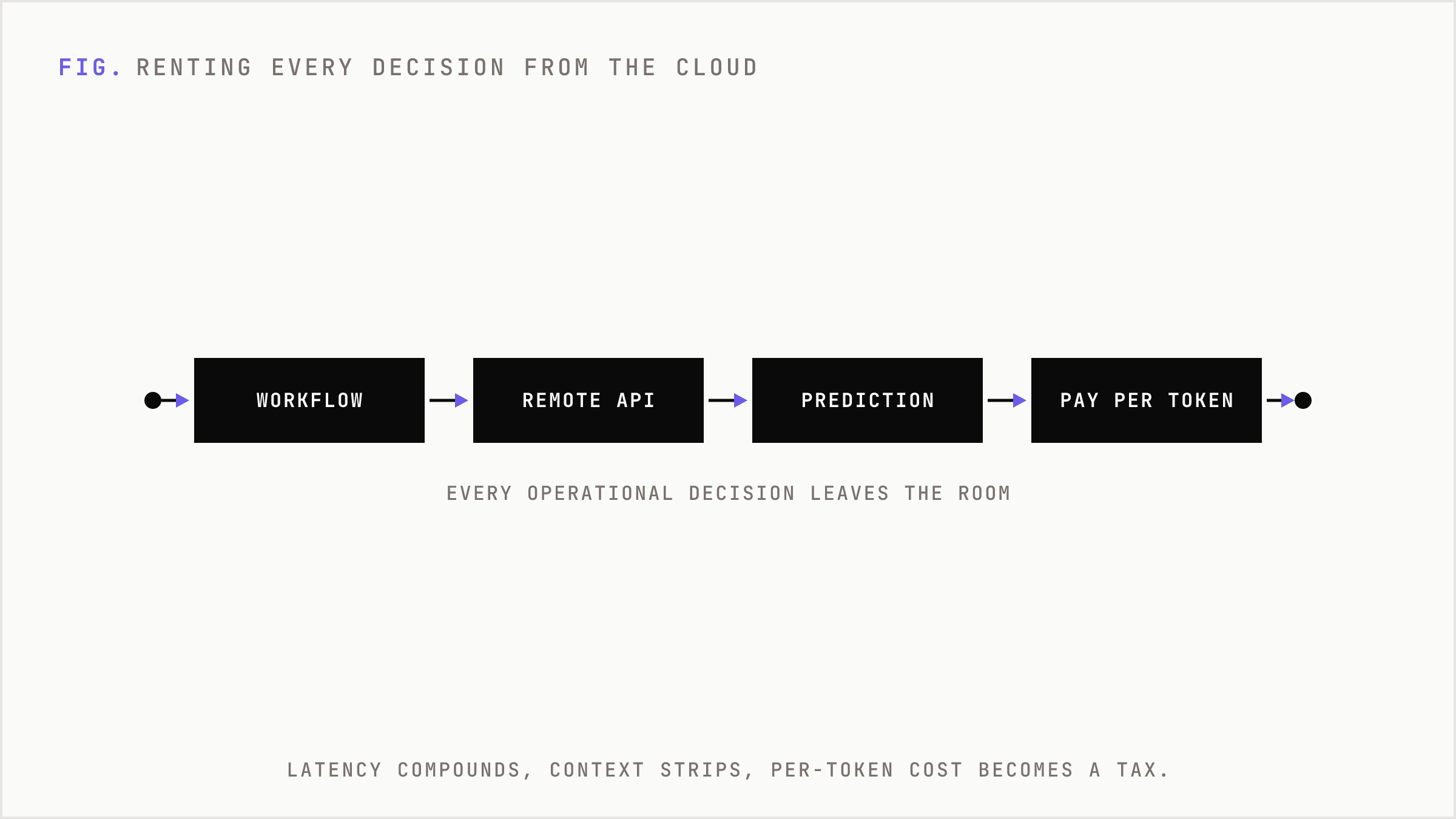
That pattern is rational for building. Shared cloud infrastructure gives teams fast access to powerful models, strong tooling, broad experimentation, and a growing ecosystem of evaluation and observability products. If you are testing a new content workflow, building an analyst agent, or prototyping a lifecycle assistant, remote inference is often the fastest path to evidence.
It breaks when every operational decision has to leave the room.
The failure is not philosophical. It is mechanical. Sensitive customer data moves across more systems. Latency compounds inside real-time experiences. Per-token costs become an operating tax. Context gets stripped because the full local state is too expensive, too risky, or too messy to ship. Teams start designing around API economics instead of customer behavior.
I keep seeing the same mistake in AI operating plans. Teams treat the model provider as the operating system. It is not. It is one component. The operating system is the spine that decides what data the model sees, what it is allowed to do, where its output goes, and how the business measures the result.
For marketing teams, this is not an infrastructure footnote. If an AI agent writes lifecycle copy, scores accounts, routes sales follow-up, personalizes a landing page, or recommends an offer, the inference path is part of the customer experience. Slow inference feels like a slow site. Expensive inference narrows personalization. Uncontrolled inference creates governance debt.
The better mechanism is the Build/Operate Split
The Nyyon mechanism is the Build/Operate Split.
Build/Operate Split is a system design where model creation, evaluation, and governance stay centralized while inference runs where the business outcome happens.
The build plane is where you select models, define tasks, create evaluation sets, test prompts, manage brand rules, tune smaller models, and decide what good output means. It benefits from shared compute, specialist tooling, and senior review. This is where teams should be opinionated and slow enough to avoid creating noise at scale.
The operating plane is where the model executes. It can be on a device, in a browser, inside a private cloud environment, on an on-prem server, or at the edge of a product experience. The point is not nostalgia for owned hardware. The point is putting inference inside the same trust boundary as the workflow.
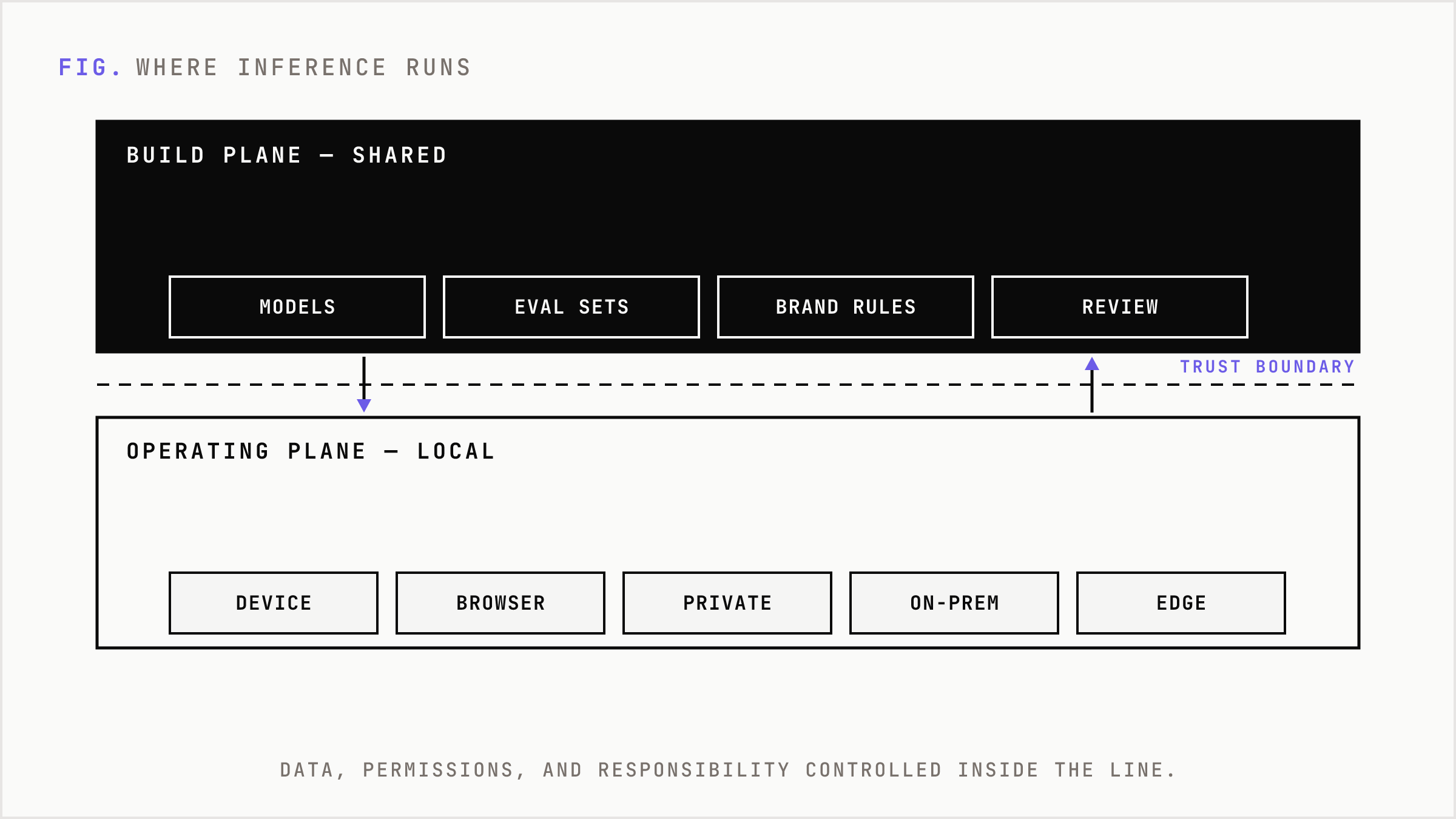
A trust boundary is the line that defines where data, permissions, and responsibility are controlled.
Once you draw that line correctly, the hardware conversation gets sharper. The question stops being which model is the smartest in a benchmark. The question becomes which workloads should run locally because the economics or risk profile demands it.
Most marketing use cases do not need a frontier model for every step. Classification, routing, extraction, clustering, deduplication, enrichment, short-form drafting, brand checks, product matching, audience labeling, and first-pass QA often work better as local or private inference tasks. The expensive model should be reserved for hard reasoning, synthesis, and exception handling.
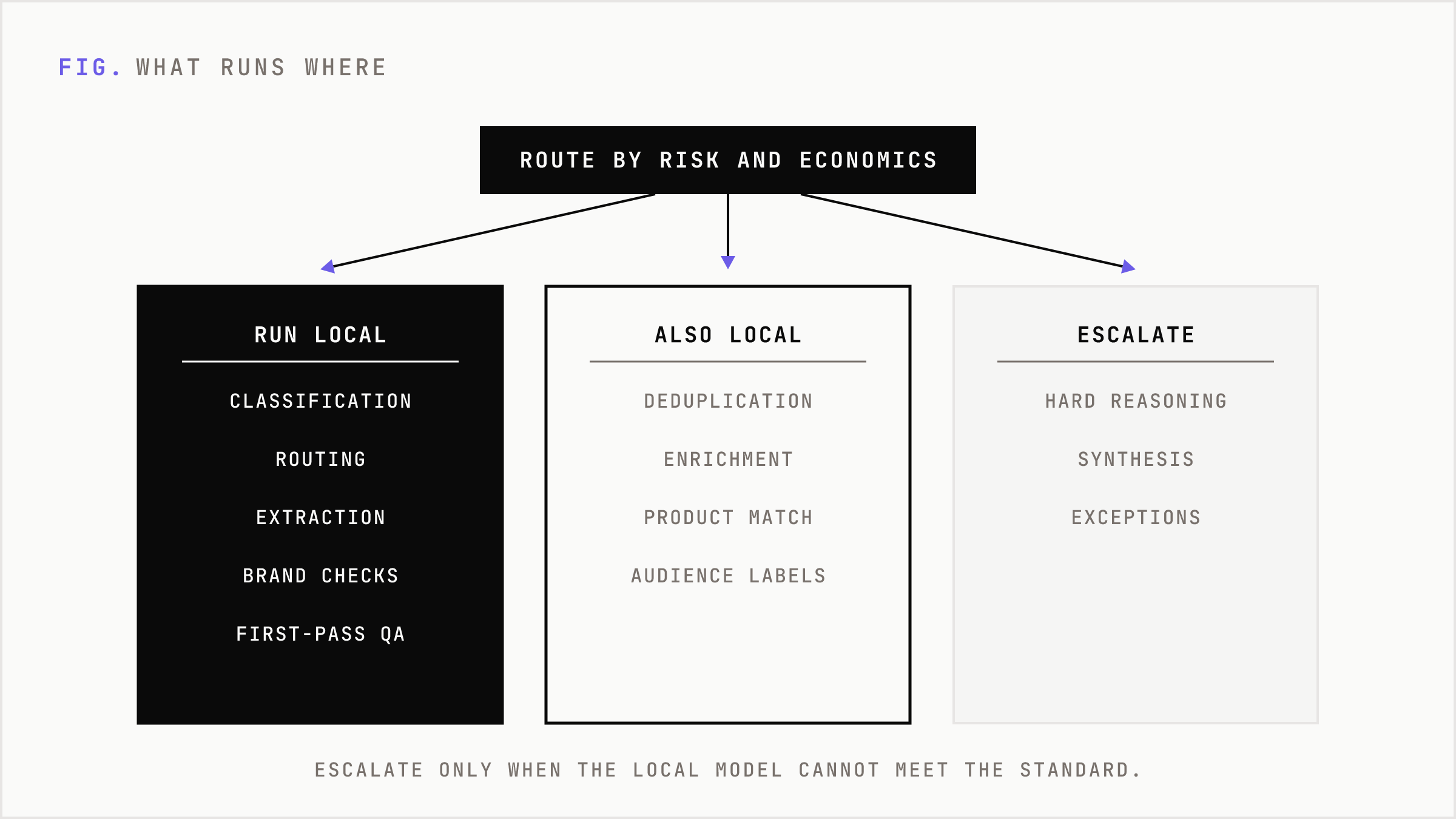
That is the split. Build with the best shared systems. Operate with the smallest reliable system close to the work. Escalate only when the local model cannot meet the standard.
Local inference changes the cost curve and the data path
The local AI inference race is really a race over three constraints: memory, latency, and trust. Hardware vendors will talk about chips. Operators should talk about where the decision runs.
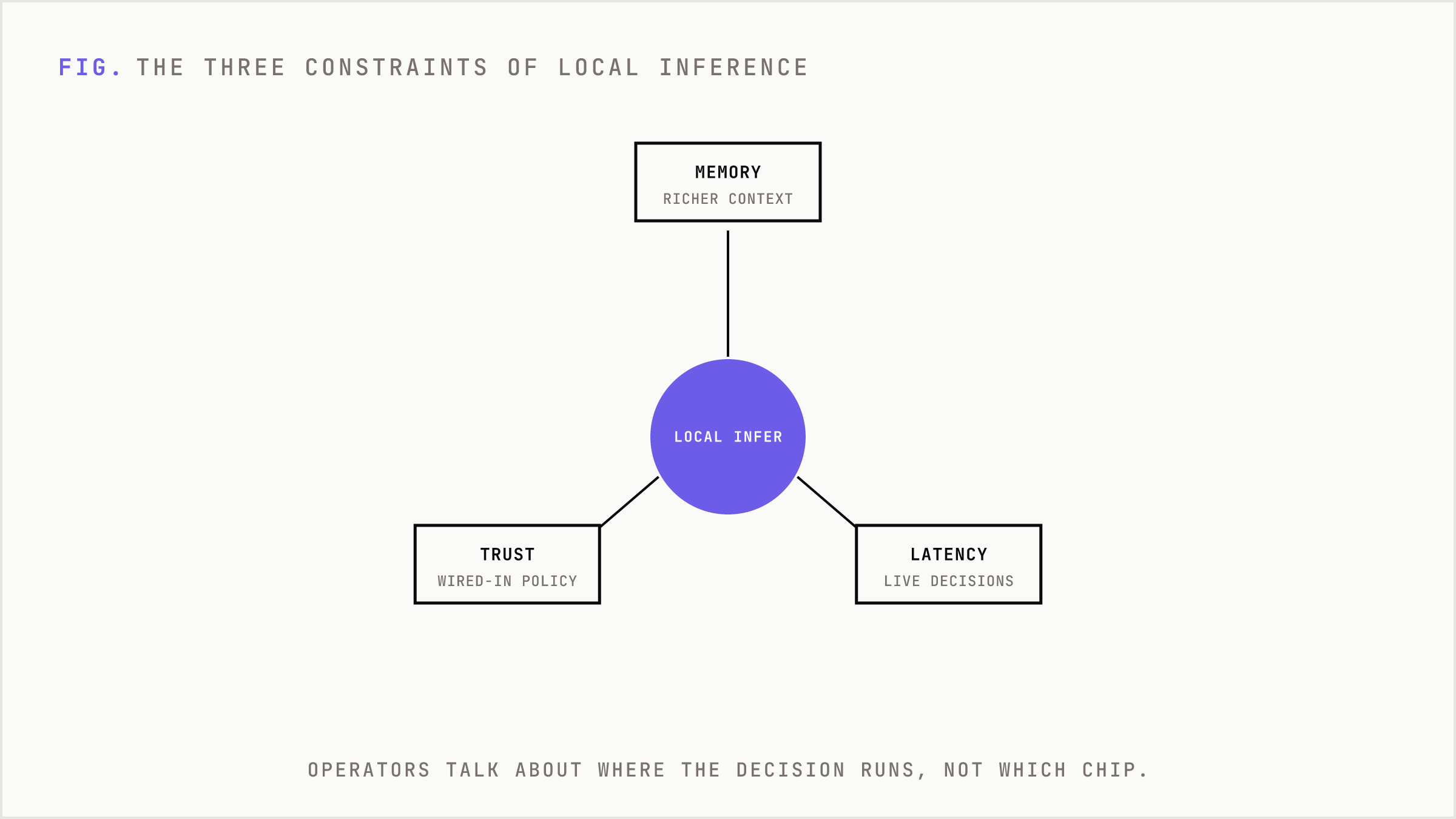
Memory matters because useful AI needs context. A lifecycle system that only sees the last email click is weak. A useful system sees product usage, plan type, onboarding state, sales notes, support issues, refund risk, consent status, and purchase history. Sending all of that to a remote model for every decision is expensive and risky. Keeping inference near the data lets the system use richer context with tighter permissions.
Latency matters because AI is moving from back-office generation into live experiences. A weekly campaign brief can wait. A pricing explanation, checkout assist, support triage, in-app activation nudge, or sales copilot recommendation cannot feel like a committee meeting. Local inference removes network dependency from the first decision. The system can still escalate to a larger model when needed.
Trust matters because AI governance is only real when it is wired into the path of execution. A policy document sitting next to a model API is theater. A local operating layer can enforce data access, redact fields, apply brand constraints, log outputs, and block unsafe actions before anything leaves the environment.
This is where the marketing data spine becomes non-negotiable.
A marketing data spine is the governed system that connects customer identity, spend, revenue, metrics, and activation across tools.
Local inference without a spine becomes a pile of edge tricks. A model in a browser. A model in a CRM. A model in support. Each one sees a fragment and optimizes a fragment. The result is fast local noise.
Local inference with a spine is different. The model receives governed context. It knows which fields it can see. It writes outcomes back to a shared log. It can be evaluated against activation, retention, pipeline, profit, or resolution quality. That is how local AI becomes an operating advantage instead of a hardware hobby.
A concrete example: lifecycle activation without shipping the customer
Take a B2B SaaS onboarding motion. The company wants an AI system to help each new account reach activation. The old version is a fixed email journey: Day 1 welcome, Day 3 feature education, Day 7 webinar invite, Day 14 sales check-in. It treats the account as a timestamp.
The cloud-only AI version is better, but still blunt. Every day, the system packages product events, CRM notes, firmographic data, support tickets, and recent email behavior into a prompt. It sends the bundle to a remote model. The model writes the next message or recommends the next action.
That may work at small volume. At scale, four consequences show up.
Consequence 1: the richest activation context is the most sensitive context, so teams either overshare it or strip it down until the model becomes generic.
Consequence 2: every account check becomes a metered event, which makes teams reduce frequency right when they should increase responsiveness.
Consequence 3: governance gets bolted on after generation, so brand, compliance, and consent rules fight the system instead of shaping it.
Consequence 4: the learning loop is weak because the model output, the action taken, and the activation result live in separate places.
Now apply the Build/Operate Split. The team builds the activation framework centrally. It defines what activation means, which behaviors indicate momentum, which signals indicate risk, what claims the brand can make, what data fields are restricted, and what outcomes matter.
The local operating layer runs the recurring account read. A smaller model inside the governed environment classifies each account state, extracts the relevant blocker, suggests the next best action, and checks whether a message is allowed. Only ambiguous cases move to a stronger remote model. The final action and outcome return to the spine.
The change is not that AI writes prettier emails. The change is that the system can make more permitted, context-rich decisions per week without turning every decision into a cloud request. That is the performance unlock operators should care about: decision quality at higher frequency with a cleaner audit trail.
The hardware race will reward operators, not collectors
Local AI inference will create a lot of bad procurement. Some teams will buy devices and private GPUs before they understand the workload. Some will push everything local because it feels safer. Some will keep everything remote because it feels easier. All three moves are lazy.
The operator move is workload routing.
Workload routing is the practice of assigning each AI task to the smallest reliable execution environment that meets the business, security, latency, and quality bar.
Some tasks belong on a frontier model. Board-level synthesis, complex market research, multi-document reasoning, high-stakes legal review, and strategic creative exploration often need the strongest available model and senior human judgment. Running those locally just to say you are local is vanity infrastructure.
Some tasks belong near the workflow. Lead scoring refreshes, creative policy checks, taxonomy tagging, customer message classification, support intent detection, offer matching, and account-state summaries often reward speed, privacy, and volume more than maximal reasoning. These are strong candidates for local inference or private deployment.
Some tasks should not use generative AI at all. Deterministic rules, SQL, feature flags, and simple statistical models still beat LLMs when the decision is stable, auditable, and cheap. AI-native does not mean model-drunk. It means the system uses the right mechanism for the outcome.
This is why the next hardware race is local. The winning companies will not be the ones with the most AI subscriptions. They will be the ones that know which decisions deserve powerful remote intelligence, which decisions deserve local inference, and which decisions deserve no model at all.
What changes, what stays the same, and the trade-off
If you adopt the Build/Operate Split, the data path changes first. More context stays inside the business boundary. More low-level decisions happen near the customer or workflow. More model outputs become logged events instead of disposable text. The economics shift from renting every token to paying for a mix of shared model access, owned infrastructure, and operational discipline.
The team shape changes next. Marketing operations, data engineering, security, and growth cannot stay in separate rooms. The AI system crosses their boundaries. A lifecycle agent needs brand governance, event data, identity resolution, consent rules, creative review, and outcome measurement. Local inference makes those dependencies visible because the operating layer sits close to the machinery.
What stays the same is judgment. Strategy still matters. Positioning still matters. Offer quality still matters. Measurement still matters. Local inference will not save a weak product, a confused ICP, or a reporting stack that cannot connect actions to revenue. It only makes a strong operating system faster and cheaper to run.
The trade-off is real. Local inference adds operational burden. Someone has to manage model versions, device constraints, evaluation drift, fallback paths, security patches, and observability. Smaller models can fail quietly. Local systems can fragment if the spine is weak. The answer is not to romanticize local hardware. The answer is to route workloads with discipline.
For senior operators, the decision rule is simple. Build centrally when the task needs exploration, evaluation, governance, and shared expertise. Operate locally when the task needs private context, low latency, high frequency, or controlled cost. Escalate to stronger models when the local system does not meet the bar.
The hardware race will be won at the architecture layer. Chips matter because they change what can run near the work. The durable advantage belongs to teams that separate building from operating, wire local inference into the data spine, and measure the result in decisions made, outcomes improved, and risk removed.